
第五回: flex の演習
2011 年 5 月 13 日
http://www.sw.it.aoyama.ac.jp/2011/Compiler/lecture5.html
© 2005-11 Martin J. Dürst 青山学院大学
flex の概要flex の使い方と演習全て同じ力を持って、お互いに変換可能、正規言語を定義・受理
字句解析 (lexical analysis)
構文解析 (parsing; syntax analysis)
意味解析 (semantic analysis)
最適化 (optimization)
コード生成 (code generation)
前半 (解析) もしくは全体の中心は構文解析
構文解析は getNextToken()
のような関数で字句解析から必要に応じて次のトークンを取得
構文解析は必要に応じて意味解析などを呼ぶ
主な要点:
選択肢:
flex の概要lex のオープンソース版、様々な拡張lex: Unix 付属の字句解析器生成系
(作者の名前は Lesk)bison と相性がよいls: ディレクトリの内容をリストアップmkdir: 新しいディレクトリを作るcd: 現在のディレクトリを変更するpwd: 現在のディレクトリを表示するgcc: C のプログラムをコンパイルする./a: コンパイルしたプログラムを実行するnotepad filename.l &: cygwin
からメモ帳を直接、しかも並行に使用可能C:\cygwin C:\cygwin の下しか見えないC:\cygwin\home\user1pwd で /home/user1 として表示C:\cygwin からの脱出:cd /cygdrive/cflex の動作.l の flex 用入力ファイル ((f)lex
ファイル) を作成 (例: test.l)flex で test.l ファイルから
lex.yy.c ファイルを作成:flex test.llex.yy.c を (他のファイルと一緒に)
コンパイルflex の使い方main から yylex() 関数を一回呼ぶ
構文解析から yylex()
を繰り返し呼んで、トークンを return で返す
flex の勉強の仕方flex の出力 (lex.yy.c) を読むflex のソースを読む (flex
の字句解析も flex 形式で記述)flex
-v)flex の入力形式flex 専用の指示と C
プログラムの一部分が混在
主に、二つの %%
で区切られている三つの部分からなる:
C 言語そのものと違って、改行、字下げが解釈を左右
flex の入力形式の骨格宣言など (C 言語) 宣言など (C 言語) %% 正規表現 実行文 (C 言語) 正規表現 実行文 (C 言語) 正規表現 実行文 (C 言語) %% 関数など (C 言語) 関数など (C 言語)
flex の入力形式の一例 int num_lines = 0, num_chars = 0;
%%
\n ++num_lines; ++num_chars;
. ++num_chars;
%%
main()
{
yylex();
printf( "# of lines = %d, # of chars = %d\n",
num_lines, num_chars );
}
int yywrap () { return 1; }
flex の基本動作flex 呼び出し時:
.l ファイル内の C 言語の断片のコピー.l
ファイルで上のものが優先flex の演習 1前のスライドの flex 用プログラムを
.l ファイルにし、flex と gcc
で実行ファイルにし、試行
flex の演習 2一般のテキストを XML
の要素の内容にする場合には次の表に示される変換が必要
flex
でその変換と逆変換のプログラムをそれぞれ作成
| テキスト | XML |
' |
' |
" |
" |
& |
& |
< |
< |
> |
> |
flex の演習 3: 数字の発見入力をそのまま出力、しかし数字でしたら、その前に
>>>、その後に <<<
をつけるプログラムを flex で作成
入力例:
abc123def345gh
出力例:
abc>>>123<<<def>>>345<<<gh
ヒント: 正規表現でつかんだ文字列は yytext
として使用可能
flex の演習 4: 日付の字句解析提出期限と場所: 2011 年 5 月 26 日 (木) 19:00 まで O 棟 5 階の O-529 号室の前の箱に投入
提出形式:
flex の入力ファイル (.l)一般の XML ファイルを入力して、その中のものを一行ずつ分かりやすいように書き出す。
例: (入力は <letter>Hello & World!</letter> の場合)
Start tag: <letter>
Contents: Hello
Entity: &
Contents: World!
End tag: </letter>
詳細:
| 文法 | grammar | Type | 言語 | オートマトン |
| 句構造文法 | phrase structure grammar (psg) | 0 | 句構造言語 | チューリング機械 |
| 文脈依存文法 | context-sensitive grammar (csg) | 1 | 文脈依存言語 | 線形拘束オートマトン |
| 文脈自由文法 | context-free grammar (cfg) | 2 | 文脈自由言語 | プッシュダウンオートマトン |
| 正規文法 | regular grammar (rg) | 3 | 正規言語 | 有限オートマトン |
次のような言語が正規表現などで表せるのか:
a, b, c
からなる左右対象の語の言語( と )
からなる、式等のように入れ子になっている語の言語0 と 1 からなる、n
個の 0 の後 n 個の 1
の語の言語これらは全て有限オートマトンの有限のメモリの制約によって受理不可能
| 字句解析 | 構文解析 | |
| 解析対象 | 定数、識別子、予約語、演算子など | 式、文、関数など |
| 要点 | 速さ | 能力 |
| 記述方法 | 正規表現 | 文脈自由文法 |
| (自動) 解析手段 | 有限オートマトン | プッシュダウンオートマトン |
正規文法 (regular grammar):
文脈自由文法 (context free grammar):
S → aSa | bSb | c
生成する言語: 真ん中に c が一個、周りに a と b が 0 以上対照的に自由な順番で並ぶ
生成する語の例: c, aca, bcb, abaabcbaaba 等
こういう風な言語を受理するのはメモリがないため有限オートマトンでは不可能
オートマトンの機能拡張が必要
オートマトンにプッシュダウンスタックをつけよう
(pushdown stack)

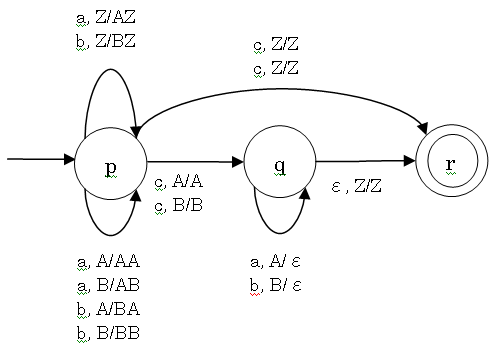
効率よく構文解析できるには可能な限り決定性のある文法が必要
中間テスト