
第四回: 正規表現と字句解析
2007年 5月 11
http://www.sw.it.aoyama.ac.jp/2007/Compiler/lecture4.html
© 2005-7 Martin J. Dürst 青山学院大学
flex -V で flex のバージョン確認gcc -v で gcc のバージョン確認 (v
は小文字)bison -V で bison のバージョン確認これらは全て同じ力を持って、正規言語を定義・受理する
これらは字句解析に使われる
| 規則の形 | 名称 |
| A → aB | 右線形規則 |
| A → Ba | 左線形規則 |
| A → a | 定数規則 |
左線形文法: 左線形規則と定数規則しか含まない文法
右線形文法: 右線形規則と定数規則しか含まない文法
左・右線形文法はともに線形文法と言い、正規文法とも言う
右線形文法と NFA の対応 (ε が考慮外):
左線形文法も同様 (語を右から読み込むと考えられる)
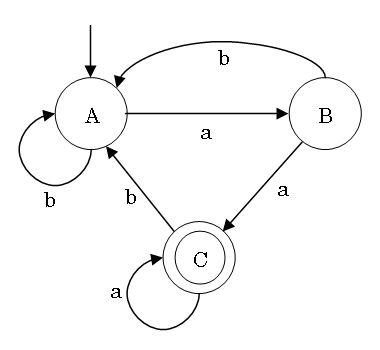
A → aB | bA
B → bA | a | aC
C → bA | a | aC
計算機実習 I の演習問題: ある文章中に
&, ", ',
<, > を見つけて、それぞれ
&, ", ', <,
> に変換せよ。
Perl で書くと次のようになる:
s/"/"/g; s/'/'/g; s/</</g; s/>/>/g; s/&/&/g;
| 優先度 | 正規表現 | 条件 | 言語 | 備考 |
|---|---|---|---|---|
| ε, a | a ∈ Σ | {ε} 又は {a} | ||
| 低い | r|s | r, s が正規表現 | L(r|s) = L(r) ∪ L(s) | 集合和 |
| 低め | rs | r, s が正規表現 | L(rs) = L(r)L(s) | 連結 |
| 高め | r* | r が正規表現 | L(r*) = (L(r))* | 閉含 |
| 高い | (r) | r が正規表現 | L((r)) = L(r) |
L(r) は r によって表されている言語。優先度は下の方が強い。
正規表現を定義する言語は文法で書けるが、正規表現は文法と違って規則は一つしか使わない。
word(aa)*a)、偶数
((aa)*)、3で割れば余りが 2
(aa(aaa)*)、等abc(a|b|c)*(a|b|c)*abc(a|b|c)*abc(a|b|c)*正規表現の便利な追加機能
.: 文字一個 (a|b|c|...)+: 一個以上の r
(rr*)?: r の有無 (r|ε,
その代わり ε は使わない){m,n}:
m 個以上 n 個以下の r
(r...rr?...r?)[b-f]: b から f の字 (b|c|d|e|f)\* 等: \
はエスケープに使われる正規表現の使い方による変更
^ と $
で語の先頭と最後をマッチ正規表現に対応する NFA は正規表現の部分表現から再帰的に作られる。
ε と a に対応する NFA は初期状態一つと受理状態一つとそれを結ぶ ε 又は a と書かれた矢印。
r|s の NFA は r の NFA と s の NFA から次のようにつくる:
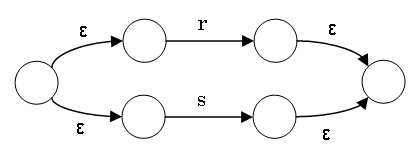
rs の NFA は r の受理状態と s の初期状態を ε で結んで、r の初期状態は rs の初期状態、s の受理状態は rsの受理状態。
r* の NFA は次のようにつくる:
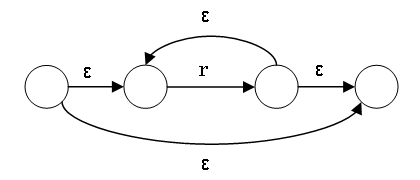
変換は可能だけど、面倒くさい。
変換の原理:
字句解析 (lexical analysis)
構文解析 (parsing; syntax analysis)
意味解析 (semantic analysis)
最適化 (optimization)
コード生成 (code generation)
前半 (解析) もしくは全体は構文解析が中心
構文解析は getNextToken() みたいな関数で字句解析から必要におおじてトーケンを取り寄せる
構文解析は必要におおじて意味解析などを呼ぶ
主な要点:
選択肢:
提出期限と場所: 2007年5月17日 (木) 19:00 まで O棟5階のO529 号室の前の箱に投入
提出は A4 の紙一枚 (裏も使ってよい)
b(a|c)*a
(提出不要)
予定:
準備: